Bootstrapping a Kubernetes Cluster
Rohit Kumar
•
26 February 2026
•
12 mins
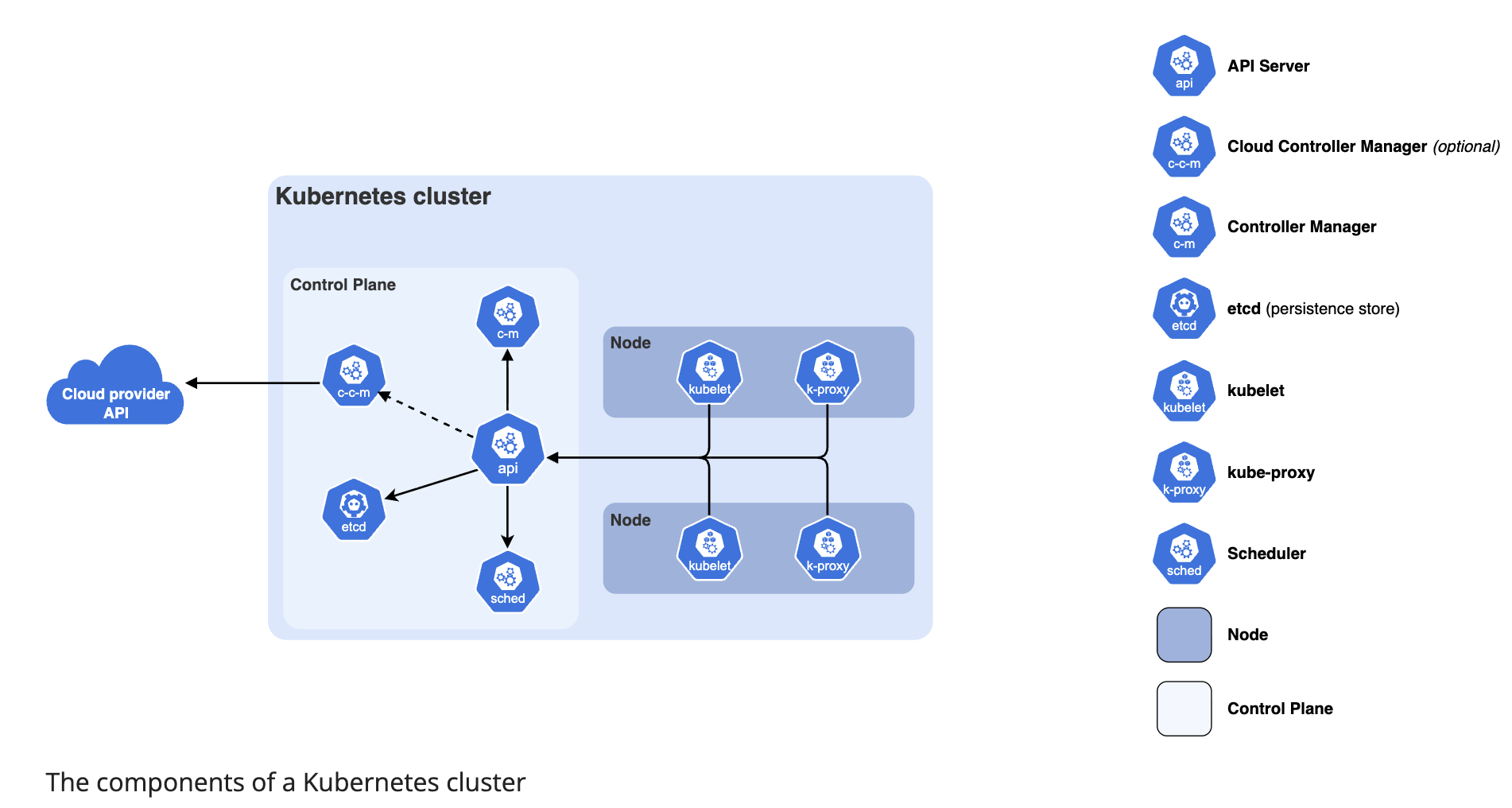
Complete Guide: Bootstrapping a Kubernetes Cluster for Production
Based on the course transcript, here is a comprehensive, structured guide for setting up a production-ready multi-node Kubernetes cluster using kubeadm.
Prerequisites
Every node (control plane and workers) must meet these requirements:
- Compatible Linux host (Ubuntu 22.04 or CentOS 7 recommended)
- Minimum 2 GB RAM per machine
- Minimum 2 CPUs on the control plane node
- Full network connectivity between all machines
- Unique hostnames, MAC addresses, and product UUIDs per node
Phase 1: Prepare All Nodes
Run every command in this phase on all nodes (control plane + workers).
Step 1 — Load Required Kernel Modules
# Create persistent module config
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
# Activate modules immediately (no reboot needed)
sudo modprobe overlay
sudo modprobe br_netfilter
Why:
overlay— Storage driver used by container runtimes like containerd to manage image layers efficientlybr_netfilter— Enables the kernel to process network packets from bridged interfaces, required by kube-proxy and CNI plugins
Step 2 — Configure Sysctl for Networking
# Create persistent kernel settings
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# Apply immediately
sudo sysctl --system
Why: These settings ensure iptables correctly processes bridge traffic, which is critical for kube-proxy and CNI networking.
Step 3 — Install containerd (Container Runtime)
# Update package list
sudo apt-get update
# Install containerd
sudo apt-get install -y containerd
Step 4 — Configure containerd
# Create config directory
sudo mkdir -p /etc/containerd
# Generate default config
sudo containerd config default | sudo tee /etc/containerd/config.toml
# Set SystemdCgroup = true (CRITICAL)
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' \
/etc/containerd/config.toml
⚠️ Critical: The kubelet and container runtime must use the same cgroup driver (
systemd). A mismatch causes cluster instability.
# Restart and enable containerd
sudo systemctl restart containerd
sudo systemctl enable containerd
Step 5 — Disable Swap
# Disable swap immediately
sudo swapoff -a
# Make persistent across reboots (comment out swap line)
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
⚠️ Note: If you reboot a node, re-run
sudo swapoff -a. The kubelet requires swap to be disabled for predictable resource management.
Step 6 — Install Kubernetes Binaries
# Install dependencies
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
# Create keyring directory (if it doesn't exist)
sudo mkdir -p -m 755 /etc/apt/keyrings
# Download and register the Kubernetes signing key
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.34/deb/Release.key | \
sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
# Add the Kubernetes apt repository
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] \
https://pkgs.k8s.io/core:/stable:/v1.34/deb/ /' | \
sudo tee /etc/apt/sources.list.d/kubernetes.list
# Update package list
sudo apt-get update
# Install the Kubernetes tools
sudo apt-get install -y kubelet kubeadm kubectl
# Hold packages to prevent accidental upgrades
sudo apt-mark hold kubelet kubeadm kubectl
Why hold packages? Accidental upgrades can break cluster version consistency, which causes serious instability.
Phase 2: Set Up the Load Balancer (HA Production Requirement)
A single control plane node is a single point of failure. For production, place a load balancer in front of multiple control plane nodes.
Load Balancer Configuration Requirements
| Setting | Value |
|---|---|
| Protocol | TCP |
| Frontend Port | 6443 |
| Backend Port | 6443 |
| Backend Targets | Private IPs of all control plane nodes |
| Health Check | TCP on port 6443 |
Phase 3: Initialize the Control Plane
Run only on the control plane node.
Step 1 — Initialize the Cluster
# Get the control plane node's private IP
ip addr show # note your private IP
# Initialize with HA load balancer endpoint
sudo kubeadm init \
--control-plane-endpoint "<LOAD_BALANCER_IP>:6443" \
--upload-certs \
--apiserver-advertise-address=<CONTROL_PLANE_PRIVATE_IP> \
--pod-network-cidr=192.168.0.0/16
Flag explanations:
| Flag | Purpose |
|---|---|
--control-plane-endpoint |
Points all nodes to the load balancer as the API server endpoint |
--upload-certs |
Securely shares cluster certificates with additional control plane nodes |
--apiserver-advertise-address |
The IP other nodes use to reach this control plane |
--pod-network-cidr |
IP range for pod networking — 192.168.0.0/16 is Calico’s default |
Step 2 — Save the Join Commands
The kubeadm init output provides two important commands. Save both:
# Additional control plane nodes use this:
kubeadm join <LB_IP>:6443 --token <token> \
--discovery-token-ca-cert-hash sha256:<hash> \
--control-plane --certificate-key <cert-key>
# Worker nodes use this:
kubeadm join <LB_IP>:6443 --token <token> \
--discovery-token-ca-cert-hash sha256:<hash>
Step 3 — Configure kubectl Access
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Step 4 — Install a CNI Plugin (Calico)
The cluster is not functional until a CNI is installed. CoreDNS will not start without it.
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.0/manifests/calico.yaml
Why Calico for production?
- Provides both pod networking and NetworkPolicy enforcement
- NetworkPolicy support is essential for cluster security
Verify Control Plane is Ready
# All pods should be Running
kubectl get pods -n kube-system
# Node should show Ready
kubectl get nodes
Phase 4: Join Worker Nodes
Run on each worker node with root privileges.
sudo kubeadm join <LB_IP>:6443 --token <token> \
--discovery-token-ca-cert-hash sha256:<hash>
Verify from the Control Plane
# -o wide shows internal IPs of all nodes
kubectl get nodes -o wide
Both nodes should show Ready status.
Phase 5: Production Hardening
1. Configure RBAC (Least Privilege)
Never give applications more permissions than they need.
# Create a dedicated namespace
kubectl create namespace my-app
# Create a service account
kubectl create serviceaccount app-sa -n my-app
# role.yaml — read-only pod access
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: my-app
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
# rolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: my-app
subjects:
- kind: ServiceAccount
name: app-sa
namespace: my-app
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
kubectl apply -f role.yaml
kubectl apply -f rolebinding.yaml
# Verify permissions
kubectl auth can-i list pods \
--as=system:serviceaccount:my-app:app-sa -n my-app
2. Apply Default-Deny Network Policies
# deny-all.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-all
namespace: my-app
spec:
podSelector: {} # selects ALL pods
policyTypes:
- Ingress
- Egress
kubectl apply -f deny-all.yaml
Then add explicit allow rules only for required communication paths.
3. Set Resource Requests and Limits on All Workloads
resources:
requests:
cpu: "200m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "512Mi"
⚠️ Critical chain: Missing
requests→ HPA cannot function. Requests too high → pods stuckPending. Limits too low → pods killed withOOMKilled.
4. Configure Health Probes
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 15
periodSeconds: 20
| Probe | Purpose |
|---|---|
| Readiness | Removes pod from service endpoints if failing — prevents bad traffic routing |
| Liveness | Restarts container if failing — self-healing |
| Startup | Protects slow-starting apps from premature liveness kills |
Phase 6: Cluster Lifecycle Management
Backing Up etcd
Run on the control plane node. etcd holds the entire cluster state.
ETCDCTL_API=3 etcdctl snapshot save /backup/snapshot.db \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key
Restoring etcd
# 1. Stop the kubelet
sudo systemctl stop kubelet
# 2. Restore snapshot to a new directory
ETCDCTL_API=3 etcdctl snapshot restore /backup/snapshot.db \
--data-dir=/var/lib/etcd-restored
# 3. Edit the etcd static pod manifest
sudo nano /etc/kubernetes/manifests/etcd.yaml
# Find the hostPath volume for etcd-data
# Change: path: /var/lib/etcd
# To: path: /var/lib/etcd-restored
# 4. Restart kubelet
sudo systemctl start kubelet
Upgrading the Cluster
Always upgrade the control plane first, then workers one at a time.
Control Plane Upgrade
# 1. Unhold, upgrade, re-hold kubeadm
sudo apt-mark unhold kubeadm
sudo apt-get install -y kubeadm=1.34.x-*
sudo apt-mark hold kubeadm
# 2. Check upgrade plan
sudo kubeadm upgrade plan
# 3. Apply upgrade
sudo kubeadm upgrade apply v1.34.x
# 4. Upgrade kubelet and kubectl
sudo apt-mark unhold kubelet kubectl
sudo apt-get install -y kubelet=1.34.x-* kubectl=1.34.x-*
sudo apt-mark hold kubelet kubectl
# 5. Restart kubelet
sudo systemctl daemon-reload
sudo systemctl restart kubelet
Worker Node Upgrade
# --- On control plane: drain the worker ---
kubectl drain <worker-node-name> --ignore-daemonsets --delete-emptydir-data
# --- On the worker node ---
sudo apt-mark unhold kubeadm kubelet
sudo apt-get install -y kubeadm=1.34.x-* kubelet=1.34.x-*
sudo apt-mark hold kubeadm kubelet
sudo kubeadm upgrade node
sudo systemctl daemon-reload
sudo systemctl restart kubelet
# --- Back on control plane: uncordon the worker ---
kubectl uncordon <worker-node-name>
Repeat the worker upgrade process one node at a time to maintain workload availability.
Quick Reference: Key Troubleshooting Commands
| Symptom | Command |
|---|---|
Pod stuck Pending |
kubectl describe pod <name> → check Events |
Pod in CrashLoopBackOff |
kubectl logs <pod> --previous |
Node NotReady |
SSH to node → systemctl status kubelet |
| Service unreachable | kubectl describe service <name> → check Endpoints |
| DNS not resolving | Run nslookup <service> from inside a pod |
| Resource pressure | kubectl top nodes / kubectl top pods |
| Control plane issues | Check /etc/kubernetes/manifests/ for static pod configs |
Production Readiness Checklist
- All nodes have unique hostnames, MACs, and UUIDs
- Swap disabled persistently on all nodes
SystemdCgroup = truein containerd config- Kubernetes binaries on
apt-mark hold - Load balancer configured in front of control plane nodes
- CNI plugin installed (Calico recommended for NetworkPolicy support)
- etcd backup scheduled and tested
- RBAC configured with least-privilege service accounts
- Default-deny NetworkPolicy applied per namespace
- Resource requests and limits set on all workloads
- Liveness and readiness probes configured on all pods
- Metrics Server installed for HPA support